1.为什么选择Apache Solr
Apache Solr是一个功能强大的搜索服务器,它支持REST风格API。Solr是基于Lucene的,Lucene 支持强大的匹配能力,如短语,通配符,连接,分组和更多不同的数据类型。它使用 Apache Zookeeper特别针对高流量进行优化。Apache Solr提供各式各样的功能,我们列出了部分最主要的功能。
- 先进的全文搜索功能。
- XML,JSON和HTTP - 基于开放接口标准。
- 高度可扩展和容错。
- 同时支持模式和无模式配置。
- 分页搜索和过滤。
- 支持像英语,德语,中国,日本,法国和许多主要语言
- 丰富的文档分析。
安装solr
要首先让从以下位置下载最新版本的Apache Solr:
http://lucene.apache.org/solr/downloads.html
在撰写本文时,可用的稳定版本是7.4.0。
一旦Solr的zip文件下载将它解压缩到一个文件夹。提取的文件夹看起来像下面。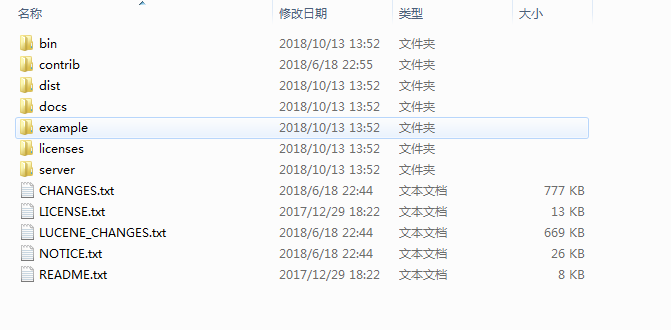
Solr的文件夹
bin文件夹中包含用来启动和停止服务器的脚本。example 文件夹包含几个示例文件。我们将使用其中的一种,以说明Solr如何索引数据。server 文件夹包含logs 文件夹,所有的Solr的日志都写入该文件夹。这将有助于索引过程来检查任何错误日志。在sever文件夹下的Solr文件夹包含不同的集合或核心(core/collection)。对于各集合或核心的配置和数据都存储在相应的集合或核心文件夹。
Apache Solr带有一个内置的Jetty服务器。但在我们开始之前,我们必须验证JAVA_HOME已经配置。
我们可以使用命令行脚本启动服务器。让我们去solr的bin目录,从命令提示符输入出以下命令1
solr start
这将启动下的默认端口8983 Solr的服务器。
现在,我们可以在浏览器中打开以下网址和验证,我们的Solr的实例正在运行。solr的管理工具的细节超出了示例的范围。
配置Apache Solr
在本节中,我们将告诉你如何配置的核心/集合作为Solr实例,以及如何定义的字段。Apache Solr附带称为无模式模式的选项。这个选项允许用户构建有效的架构,而无需手动编辑模式文件。但是,在这个例子中,我们将使用架构配置理解Solr的内部。
建立核心(core)
当Solr的服务器在独立模式下启动的配置称为核心,当它在SolrCloud模式启动的配置称为集合。在这个例子中,我们将有关独立服务器和核心讨论。我们将在以后再讨论SolrCloud。首先,我们需要创建一个核心的索引数据。Solr的创建命令有以下选项:
-c
-d
-n
-p
-s
-rf
在这个例子中,我们将使用的核心名称和配置目录-d参数-c参数。对于所有其它参数我们使用默认设置。
现在在命令窗口浏览 solr-7.4.0\bin文件夹,并发出以下命令。1
solr create -c jcg
我们可以看到在命令窗口中下面的输出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23Creating new core 'jcg' using command:
http://localhost:8983/solr/admin/cores?action=CREATE&name=jcg&instanceDir=jcg
{
"responseHeader":{
"status":0,
"QTime":663},
"core":"jcg"}
```
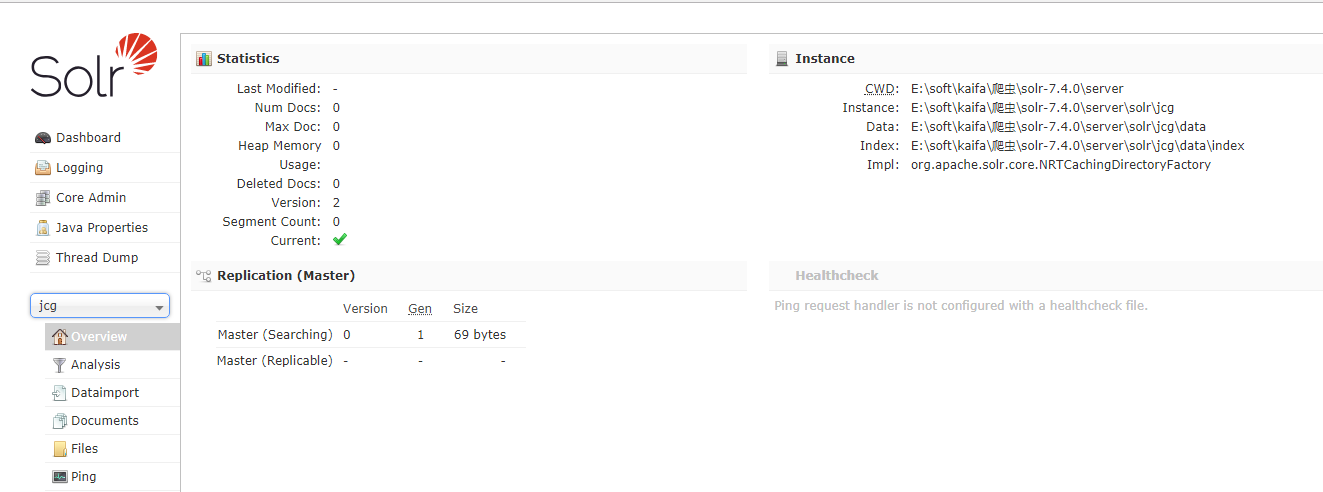
现在我们导航到以下网址,我们可以看到JCG核心被填充在核心选择器上。还可以看到核心的统计信息。
http://localhost:8983/Solr
## 修改Schema.xml文件
我们需要修改schema.xml中文件的文件夹下,server\solr\jcg\conf包含的字段。我们将使用随Solr的安装索引附带的示例文件“books.csv”之一。该文件所在的文件夹下 的solr-7.4.0\example\exampledocs
现在,我们定位到该文件夹 server\solr目录。你会看到一个名为JCG的文件夹被创建。子文件夹conf和data分别拥有核心的配置和索引的数据。
现在编辑\server\solr\jcg\conf\server\solr\jcg\conf\schema.xml文件,设置唯一元素后添加以下内容。
我们已经设置了属性索引为true。这指定字段用于索引和记录可以使用索引进行检索。该值设置为false将只存储领域,但不能进行查询。
另外请注意另一个属性stored并将其设置为true。这指定字段被存储,并且可以在输出被返回。将此字段设置为假将使字段唯一索引,并且不能在输出进行检索。
我们已经分配给存在于此处的“books.csv”文件中的字段的类型。在CSV文件“ID”第一场由索引Schema.xml文件的唯一键自动元素的照顾。如果你注意,我们已经略过字段series_t,sequence_i和genre_s未做任何条目。但是,当我们执行索引时,所有这些字段都被索引且没有任何问题。如果你想知道这种情况需要在Schema.xml文件的dynamicField部分一探究竟。
[schema.xml](schema.xml)
既然我们已经修改了配置,我们必须停止和启动服务器。要做到这一点,我们需要通过命令行发出从bin目录下面的命令。
Solr stop -all1
服务器将停止现在。现在启动服务器问题从bin目录中通过命令行运行以下命令。
Solr start`
导入数据
Apache Solr带有一个叫做SimplePostTool独立的Java程序。这个程序被打包成JAR,在安装目录下 example\exampledocs可看到。
现在,我们在命令行定位到example\exampledocs文件夹,然后键入以下命令。你会看到一堆选项,使用的工具。
正如我们前面所说,我们将索引“books.csv”文件中的数据。我们将导航到solr-7.4.0\example\exampledocs在命令提示符并发出以下命令。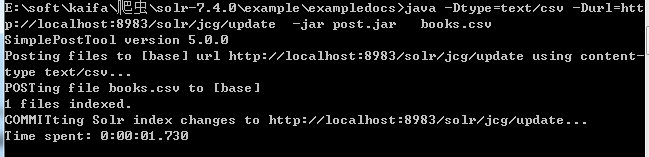
现在我们导航到以下网址并选择核心JCG。
http://localhost:8983/solr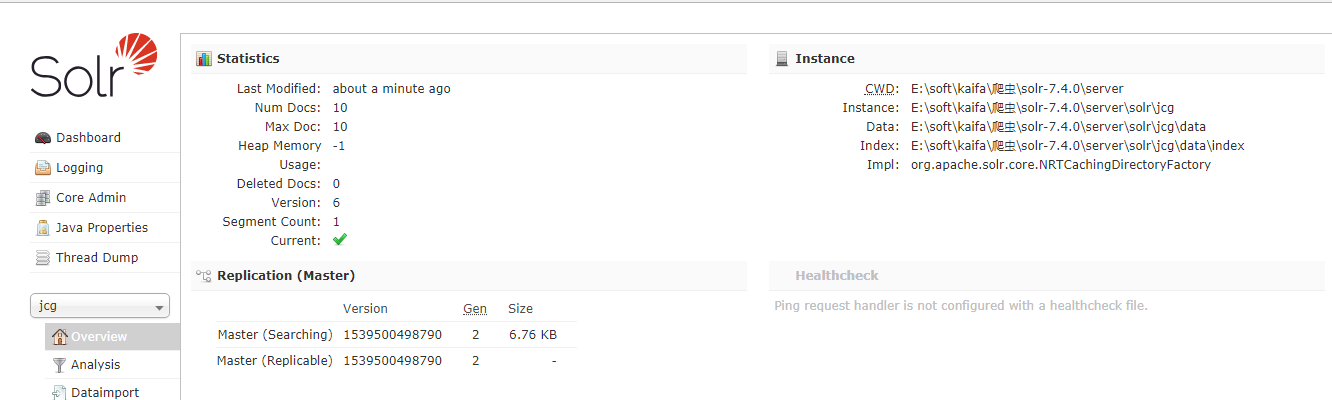
Solr的JCG核心数据
就拿在统计部分仔细一看,该民文档参数将显示索引的行数。
访问索引的文档
Apache Solr提供了一种基于REST API来访问的数据,并还提供了不同的参数,以检索数据。我们将向您展示一些基于场景的查询。
按名称搜索
我们将用它的名字检索书的细节。要做到这一点,我们将使用下面的语法。URL中的参数“Q”是查询事件。
打开浏览器下列URL。
http://localhost:8983/solr/jcg/select?q=name:"A Clash of Kings”
输出将在下面,如图所示。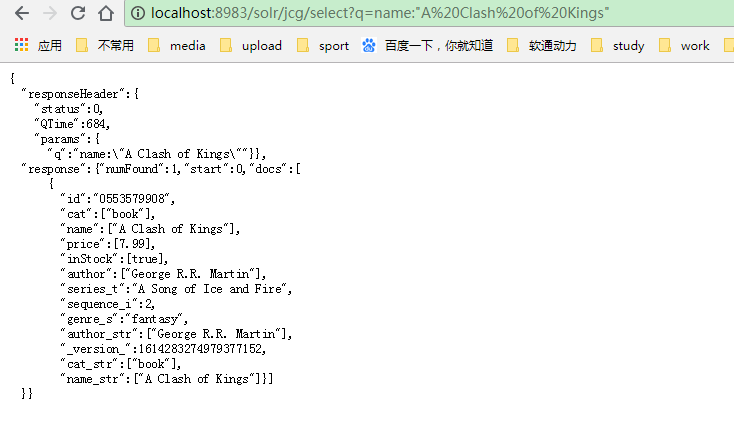
首字母搜索
现在我们将告诉你如何搜索记录,如果我们只知道起始字母或单词,不记得完整的标题。我们可以用下面的查询检索结果。
http://localhost:8983/solr/jcg/select?q=name:"A"
输出将列出所有的书籍字母A盯着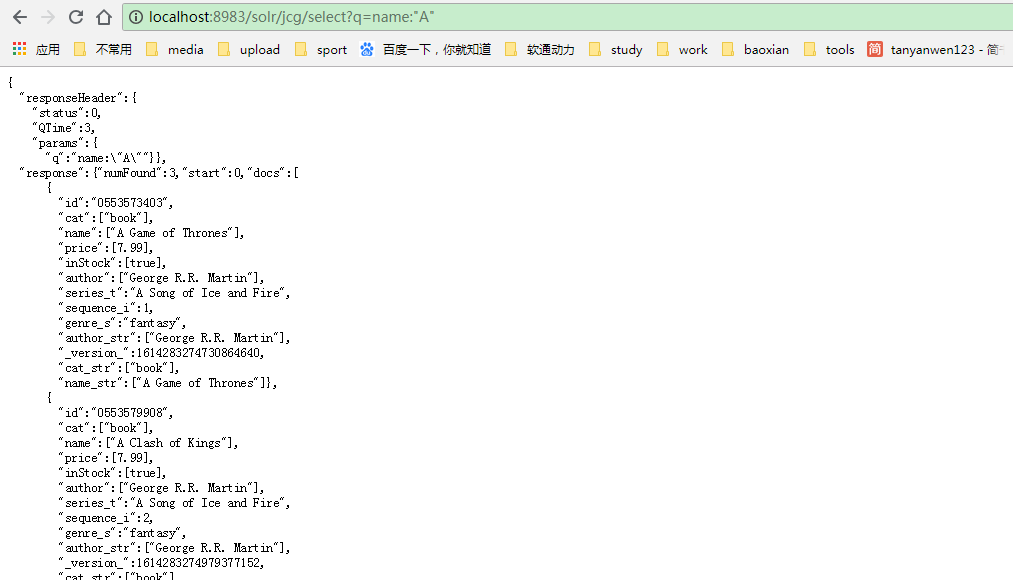
搜索使用通配符
Solr的支持通配符搜索。我们将下面的展示如何检索所有书名包含“of”的书。
http://localhost:8983/solr/jcg/select?q=name:"*of"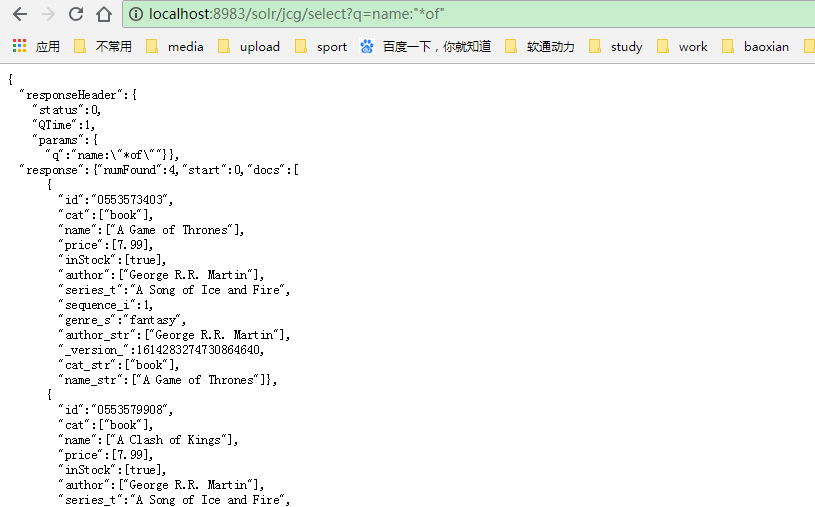
搜索使用的条件
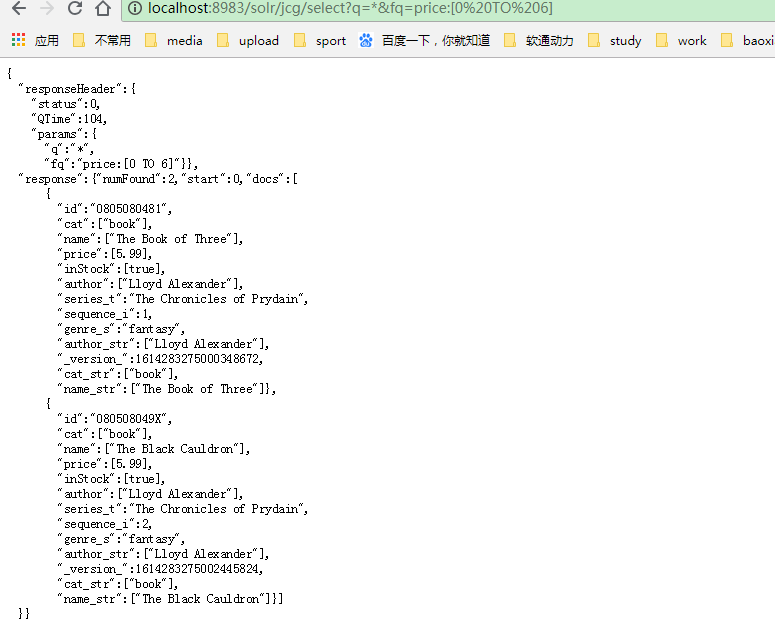
Solr的支持条件的搜索。我们可以设置条件,我们的查询提供了“FQ”参数。在下面我们将告诉你如何查询价格低于¥6的书。
http://localhost:8983/solr/jcg/select?q=*&fq=price:[0 TO 6]
输出将只列出这是低于$ 6的书籍。